
用户 一枫说码 的回答
面试中常问的一个问题就是:在浏览器输入 URL 地址回车后,发生了什么?这里简单概述一下。
总体流程图如下:
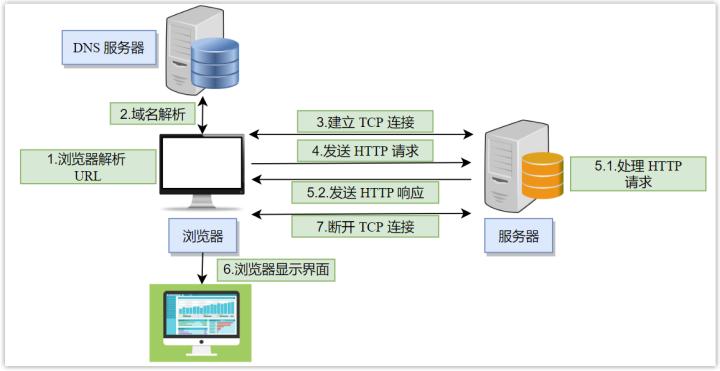

1. URL 解析
浏览器首先对 URL 解析,解析出协议、域名、端口、资源路径、参数等。

2. DNS 域名解析
一般而言,域名比 IP 地址更好记,因而我们更习惯在浏览器输入域名而不是 IP,而计算机网络通信所识别的计算机标识是 IP 地址,因而首先需要将一个域名转化为相应的 IP 地址,这就是 DNS 协议所要做的事。
DNS 就像我们手机中的通讯录一样,通讯录中备注的是对方的姓名(类似于域名),但是打电话的时候实际需要的是电话号码(类似于 IP 地址),利用通讯录将一个姓名转化为对应的电话号码。

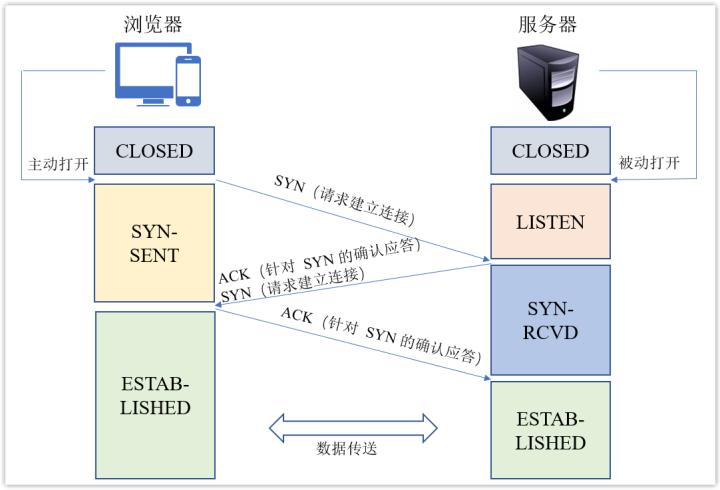
3. 建立 TCP 连接
一般在浏览器输入 URL,应用层的协议为 HTTP/HTTPS,其需要的是可靠的服务,所使用的传输层协议为 TCP。
通过域名解析后,浏览器获得了服务器的 IP,则向服务器发起 TCP 连接,这时候就会发生三次握手行为。
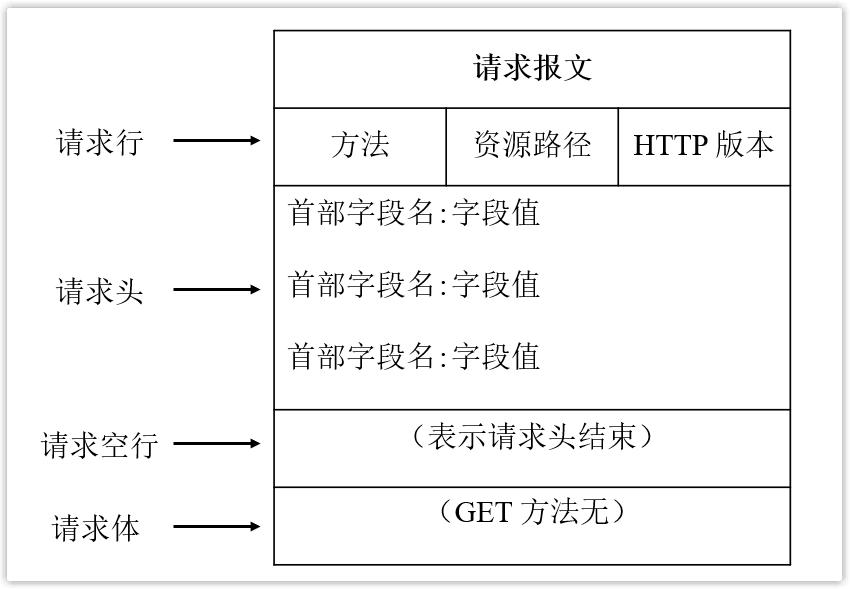
4. 发送 HTTP 请求
当浏览器与服务器建立连接后,就可以进行数据通信过程,浏览器会给服务器发送一个 HTTP 请求报文,请求报文包括请求行、请求头、请求空行和请求体。在请求行中会指定方法、资源路径以及 HTTP 版本,其中资源路径是指定所要操作资源在服务器中的位置,而方法是指定要对这个资源做什么样的操作。
从浏览器输入 URL,资源路径在第一步就已经被解析出来了,而方法为 GET,表明要获取资源,相当于增删改查中的查询。
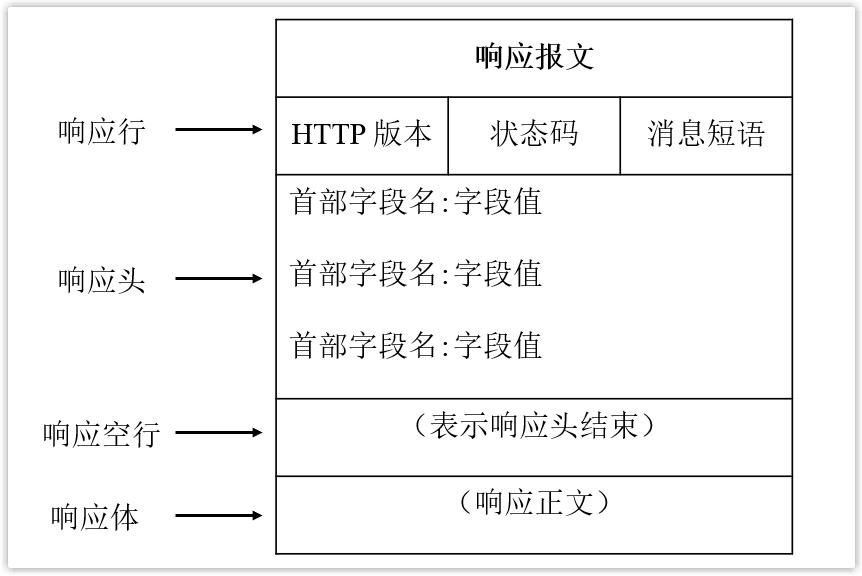
5. 服务器对请求进行处理并做出响应
当收到浏览器发送的请求报文后,服务器会对此请求报文进行相应的处理,并返回响应报文给浏览器。比如请求报文想要获取(GET) index.html 这个文件,那么服务器就会找到 index.html 文件,然后将此文件作为响应报文中的响应体发送给浏览器。
响应报文包括响应行、响应头、响应空行和响应体。在响应行中会指定 HTTP 版本、状态码和对状态码的解释信息,比如 HTTP/1.1 200 OK ,其中 200 是响应码,指请求被正常处理,也就是成功 OK 的意思。
6. 浏览器解析渲染页面
浏览器收到服务器的响应报文后,从响应体中得到相应资源,如 HTML 文件、图片、视频等,并进行渲染,然后将结果呈现给用户。
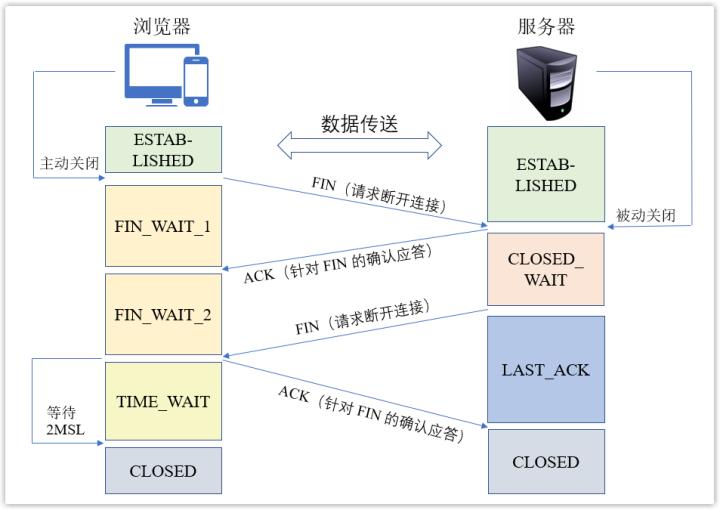
7. 断开 TCP 连接
当数据完成请求到返回的过程之后,根据请求/相应头中 Connection 的 Keep-Alive 属性可以选择是否断开 TCP 连接,如果不需要再进行数据通信,即可以关闭连接,此时则会发生四次挥手行为。
注意:
- 浏览器为了提升性能,在 URL 解析之后,实际会先查询是否有缓存,如果缓存命中,则直接返回缓存资源。
- 如果是 HTTPS 协议,在建立 TCP 连接之后,还需要进行 SSL/TLS 握手过程,以协商出一个会话密钥,用于消息加密,提升安全性。
用户 会点代码的大叔 的回答
谢邀~
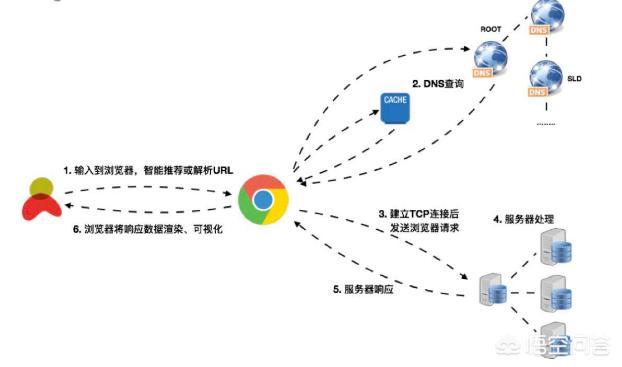
我们打开浏览器,在地址栏输入\www.wukong.com\,几秒后浏览器打开悟空问答的页面,那么这几秒钟内发生了哪些事情,我就带大家一起看看完整的流程:
解析URL
浏览器首先会对输入的URL进行验证,如果不合法的时候,那么会把输入的文字传给默认的搜索引擎,比如你只在地址栏输入“悟空问答”几个字。
如果URL通过验证,那么可以解析得到协议(http或者https)、域名(wukong)、资源(首页)等信息。
DNS查询
-
浏览器会先检查域名信息是否在缓存中。
-
再检查域名是否在本地的Hosts文件中。
-
如果还不在,那么浏览器会向DNS服务器发送一个查询请求,获得目标服务器的IP地址。
TCP封包及传输
这时候浏览器获得了目标服务器的IP(DNS返回)、端口(URL中包含,没有就使用默认),浏览器会调用库函数socket,生成一个TCP流套接字,也就是完成了TCP的封包。
TCP封包完成之后,就可以传输了,在完成“你瞅啥”,“瞅你咋地”,“来,过来唠唠”一系列操作之后,浏览器和服务器就完成了TCP的三次握手,建立了连接,后面就可以请求服务器资源了。
服务器接收请求并相应
-
HTTP有很多请求方法,比如:GET/POST/PUT/DELETE等等,我们浏览器输入URL这种,是GET方法。
-
服务器接收到GET请求,服务器根据请求信息,获得相应的相应内容。例如我们输入的是:\www.wukong.com\,那么意味着访问首页文件。
浏览器解析并渲染
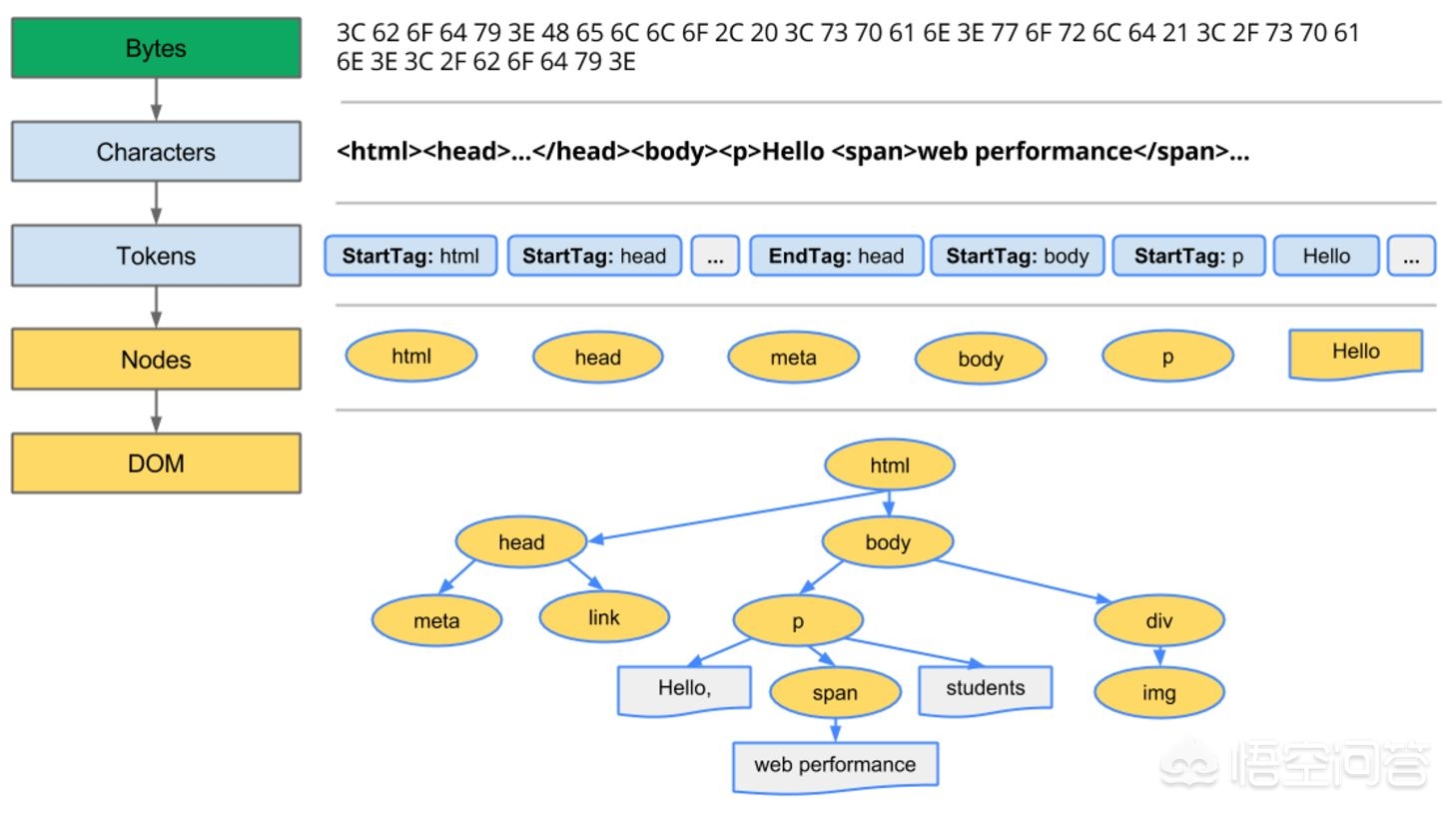
浏览器从服务器拿到了想要访问的资源,大多数时候,这个资源就是HTML页面,当然也可能是一个其他类型的文件。
-
浏览器先对HTML文档进行解析,生成解析树(以DOM元素为节点的树)。
-
加载页面的外部资源,比如JS、CSS、图片。
-
遍历DOM树,并计算每个节点的样式,最终完成渲染,变成我们看到的页面。
这次请求响应之后,会断开连接,就这样,完成了一次HTTP的请求。
我将持续分享Java开发、架构设计、程序员职业发展等方面的见解,希望能得到你的关注。

用户 全网同名IT老哥 的回答
前言
今天我们来彻底聊聊,什么是TCP/IP、http、socket、长连接、短连接
TCP/IP
TCP/IP是协议组,分为三个层次:
- 网络层
- 传输层
- 应用层。
在网络层有:
- IP协议
- ICMP协议
- ARP协议
- RARP协议
- BOOTP协议
在传输层中有:
- TCP协议
- UDP协议
在应用层有:
TCP包括:
- FTP协议
- HTTP协议
- TELNET协议
- SMTP协议
UDP包括:
- DNS协议
- TFTP协议
短连接
流程:连接->传输数据->关闭连接
HTTP是无状态的,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。
也可以这样说:短连接是指SOCKET连接后发送后接收完数据后马上断开连接。
长连接
流程:连接 -> 传输数据 -> 保持连接 -> 传输数据 -> 。。。-> 关闭连接。
长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
http的长连接
HTTP也可以建立长连接的,使用Connection:keep-alive,HTTP 1.1默认进行长连接。
HTTP1.1 和 HTTP1.0 相比较而言,最大的区别就是增加了长连接支持(貌似最新的 http1.0 可以显示的指定 keep-alive),但还是无状态的,或者说是不可以信任的。
什么时候用长连接,短连接?
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。
每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多。
所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。
例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源。
而像WEB网站成千上万甚至上亿客户端的频繁连接,用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。
所以并发量大,但每个用户无需频繁操作情况下需用短连好。
总之,长连接和短连接的选择要视情况而定。
数据发送接收方式
异步
报文发送和接收是分开的,相互独立的,互不影响。这种方式又分两种情况:
- 异步双工:接收和发送在同一个程序中,由两个不同的子进程分别负责发送和接收
- 异步单工:接收和发送是用两个不同的程序来完成。
同步
报文发送和接收是同步进行,既报文发送后等待接收返回报文。
同步方式一般需要考虑超时问题,即报文发出去后不能无限等待,需要设定超时时间,超过该时间发送方不再等待读返回报文,直接通知超时返回。
在长连接中一般是没有条件能够判断读写什么时候结束,所以必须要加长度报文头。读函数先是读取报文头的长度,再根据这个长度去读相应长度的报文。
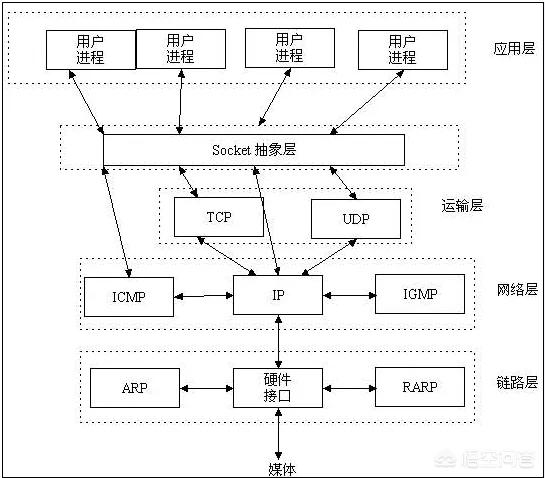
Socket是什么
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口(TCP/IP是协议,Socket是他们的具体实现和对外api)。
在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面。
对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
Socket 通信示例
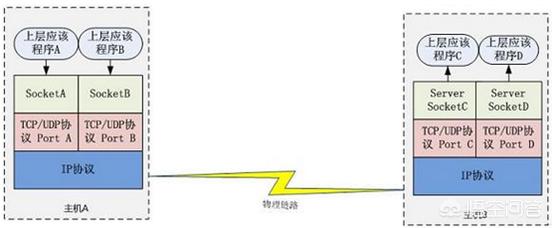
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层 TCP/IP 协议来建立 TCP 连接。
建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。
我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。
这样就可以通过一个 Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
建立通信链路(有点烧脑,可绕过)
当客户端要与服务端通信,客户端首先要创建一个 Socket 实例,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地和远程地址和端口号的套接字数据结构。
这个数据结构将一直保存在系统中直到这个连接关闭。在创建 Socket 实例的构造函数正确返回之前,将要进行 TCP 的三次握手协议,TCP 握手协议完成后,Socket 实例对象将创建完成,否则将抛出 IOException 错误。
与之对应的服务端将创建一个 ServerSocket 实例,ServerSocket 创建比较简单只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是“*”即监听所有地址。
之后当调用 accept() 方法时,将进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构,该套接字数据的信息包含的地址和端口信息正是请求源地址和端口。
这个新创建的数据结构将会关联到 ServerSocket 实例的一个未完成的连接数据结构列表中,注意这时服务端与之对应的 Socket 实例并没有完成创建,而要等到与客户端的三次握手完成后,这个服务端的 Socket 实例才会返回,并将这个 Socket 实例对应的数据结构从未完成列表中移到已完成列表中。所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的 TCP 连接。